本文来自。
刚接触的用户,可能会认为有数只是一款数据可视化工具,但其实有数不单单能可视化数据,还能对数据进行计算分析,实现复杂的数据分析需求。
本文要介绍的就是有数提供的众多数据分析功能之一—— 跨视图粒度计算(其实就是简单的3个函数,但能实现复杂的分析需求:比如新客贡献分析、留存分析、复购分析、RFM分析等等)。
既然要跨视图粒度计算,那我们先来理解两个概念: 粒度、视图。
1、粒度:什么是数据粒度呢,它指的是一份数据的细化程度,这么解释有些抽象,可以看下我制作的一幅漫画(原漫画来自日和动漫)

漫画中,老板的“粗略”、“明细”描述的就是数据的粒度,越明细的数据包含的信息越多,同时也越难解读,所以一般根据需求不同会挑选不同粒度的数据来分析。
2、视图:数据库技术里有对视图的定义,本文中,可以先简单地把视图理解为有数中的一个图表,如下图所示就是两个不同粒度的视图,视图1 细化到省,视图2细化到城市,视图2的细化程度更高,数据更明细,包含的信息也更多: 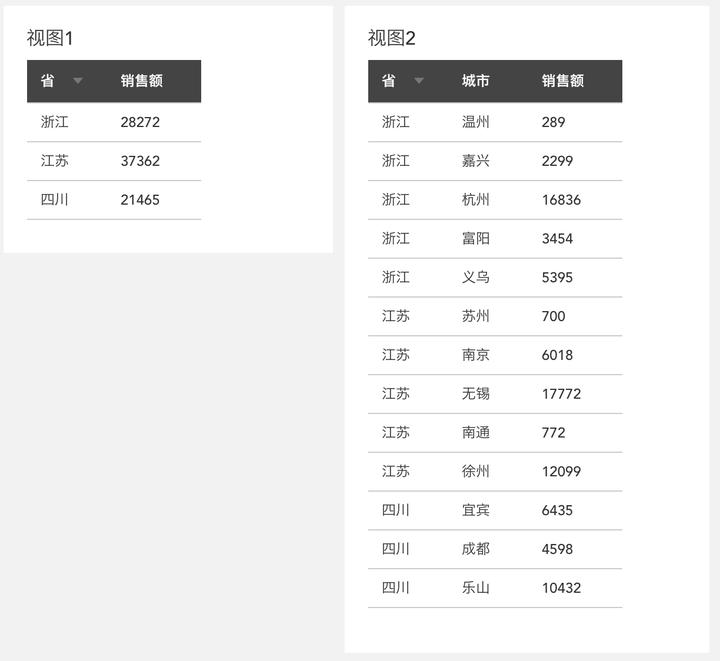
好了,现在我们已经理解了 粒度、视图两个概念,每个视图有自己的粒度,一个视图里只能有一个粒度。
那什么时候需要用到跨视图粒度计算呢,当我们在一个视图里需要用到来自其他视图粒度的数据时,就需要用到跨视图粒度计算了。举个例子:
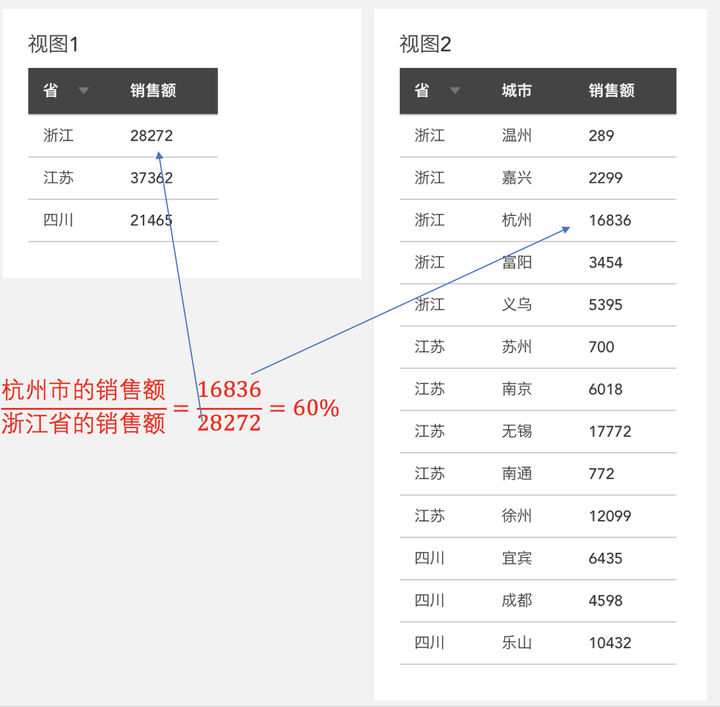
例1:还是上文的视图1跟视图2,当我们需要在视图2里加一列数据,显示每个城市销售额在该省的占比,比如计算杭州的销售额占浙江省的比例,这时候我们需要“杭州的销售额/浙江的销售额”,但杭州的销售额数据在视图2里,而浙江的销售额数据在视图1里。没法拿到一起计算:
这时候我们可能需要用SQL去取两个不同粒度视图的数据,然后放在一个视图里进行分析,SQL语句如下所示,如果不了解SQL可以忽略,不影响理解跨视图粒度计算。

但其实在有数里,如果在视图2中,需要用到视图1的数据,只需要借助一个简单的函数就可以实现
创建一个计算字段:
{ FIXED [省] : sum( [销售额]) }它的意思是以“省”的粒度计算销售额的和,也就得到每个省的总销售额。
得到每个省的总销售额之后,我们可以用城市的销售额除以省的总销售额来计算占比啦,如下:
sum( [销售额]))/sum( [各省的销售额]))
如此,我们便实现了目的,在视图2中增加一列展示每个城市的销售额在该省的占比:

有数里一个函数,就实现了本需要写那么长一串SQL语句才能办到的事,是不是很高效,不懂SQL的小伙伴也可以掌握。
例2:再举一个跨视图粒度计算的例子来帮大家理解,假设我们有这样一个视图,记录客户每个订单发生的时间,粒度细化到每个订单: 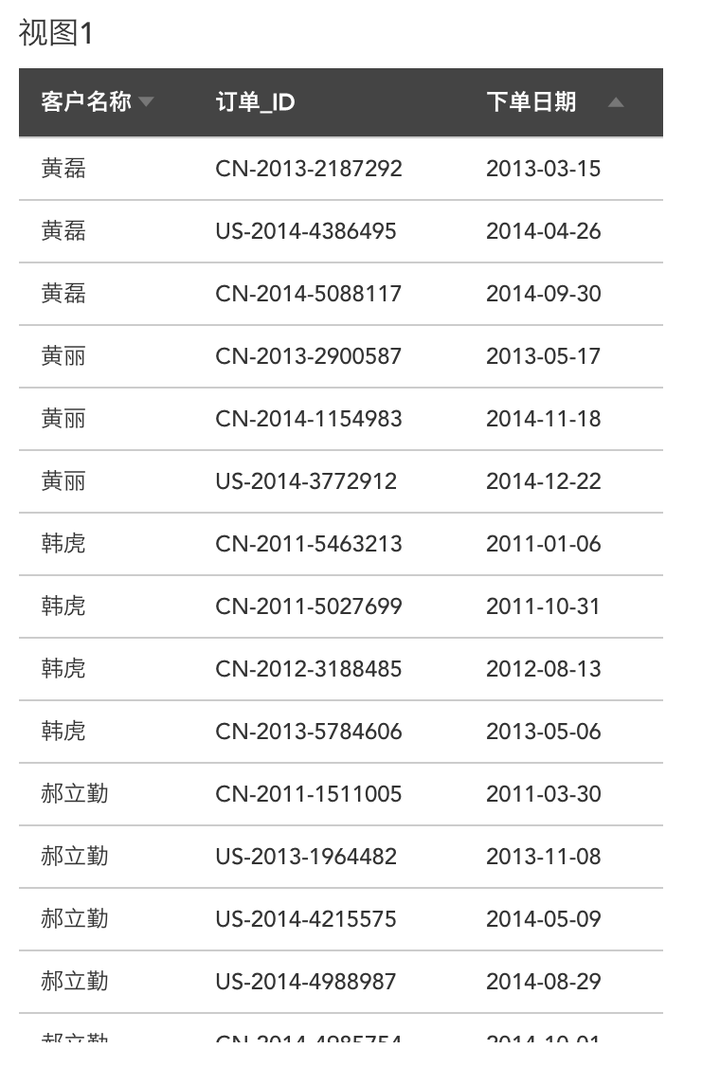
这时候,如果我想给每个订单打个标签,标记这个订单是否是新客户的首单(一个新客户下的第一单就被认为是首单),如图中标出的几个订单:
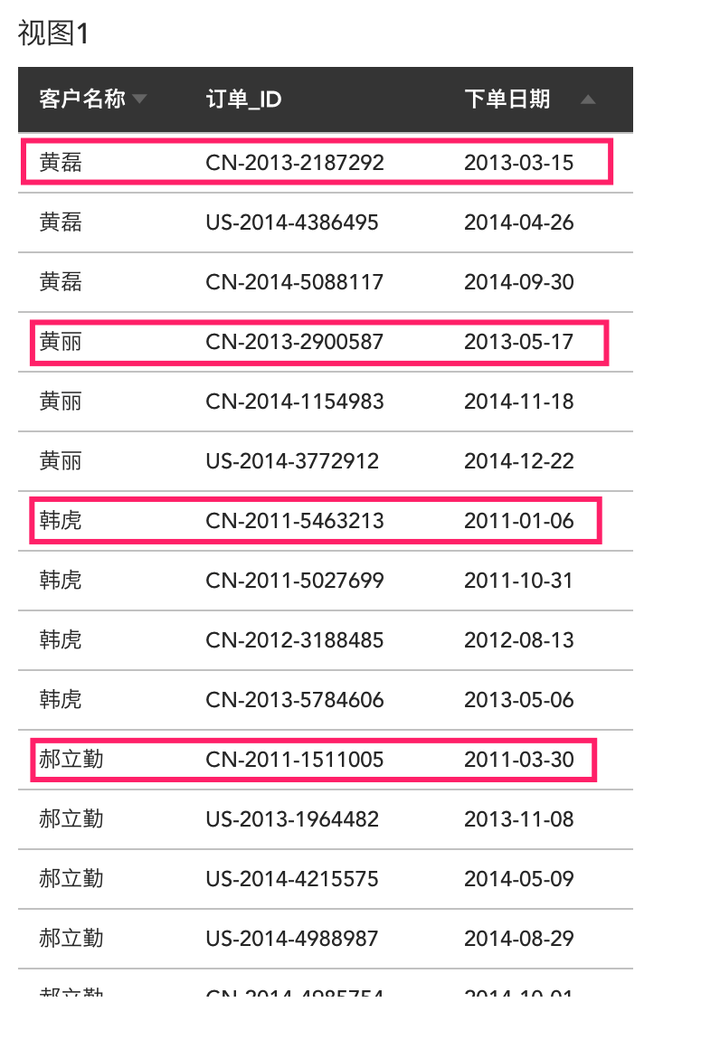
直观上理解,要判断订单是否是首单,只要把订单的时间跟客户第一次下单的时间进行对比,如果相等,说明这个订单是用户的首单,那么我们可以再建一个客户粒度的视图,对每个客户所有的下单日期取最小值,即可得到每个客户的首单日期:
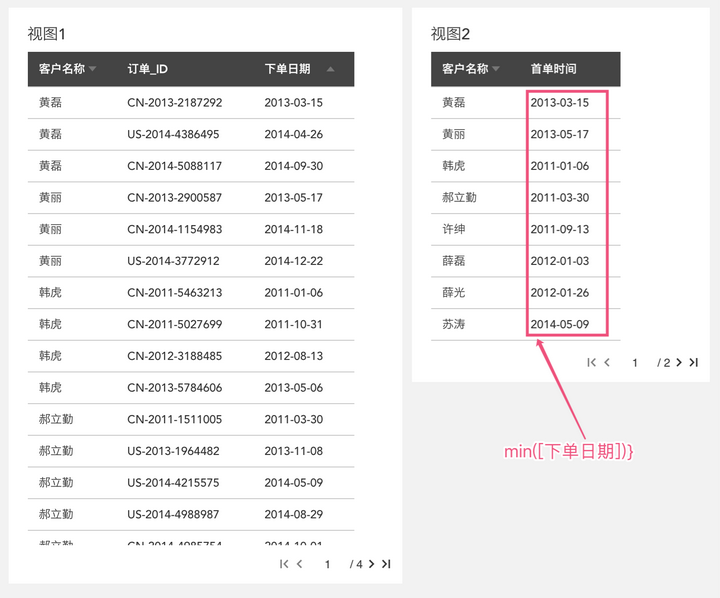
得到每个客户的首单日期后,我们只要把每个订单的日期去跟首单日期比较,如果相等就是首单,但现在遇到了难题,要比较的两个数据来自不同粒度的视图:
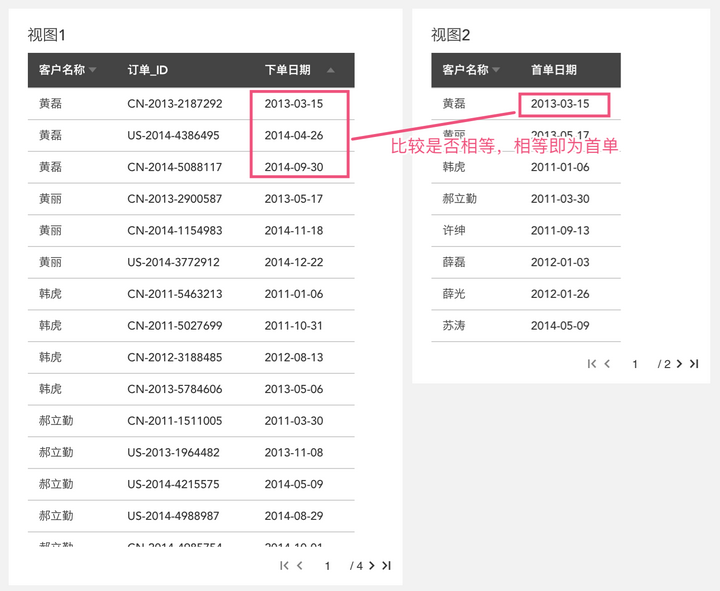
这时候,又可以借助跨视图粒度计算来实现目的啦。
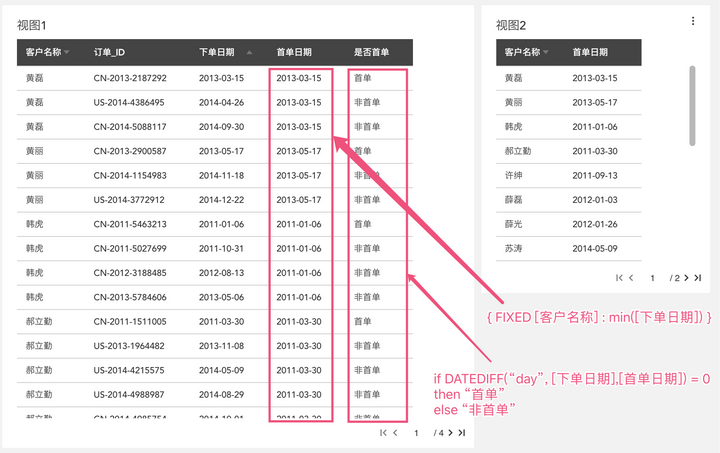
创建一个计算字段: { FIXED [客户名称] : min( [下单日期]) }
它的意思是以“客户名称”的粒度来计算最小的下单日期,也就是每个客户首单的日期,然后我们可以通过比较来给每个订单打标签啦。(我们的测试数据里,每个用户每天至多下一单,这样只要两个日期是同一天,就判定为首单,如果一天多单则还需要比较两个日期的时分秒是否一致)
if DATEDIFF( "day", [下单日期], [首单日期]) = 0 then "首单"else " 非首单"
结果如图所示:
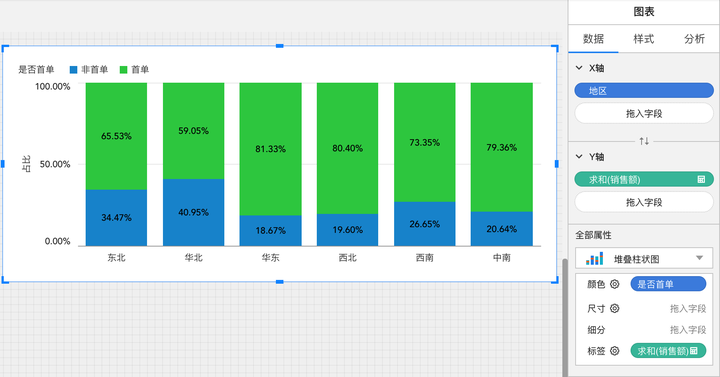
打完标签后,我们就可以在图表中直观地区别出销售额中哪些是由新客贡献的,可以看到新客贡献了大部分销售额,说明我们的老客复购效果可能不理想呀,预知后续分析,且听下回分解。
全文到这里就结束啦,有数的跨视图粒度计算是不是很灵活高效,有需要的小伙伴快去尝试吧~
:企业级大数据可视化分析平台,具有全面的安全保障、强大的大数据计算性能、先进的智能分析、便捷的协作分享等特性。
作者:汪谦 如需转载,请取得作者同意授权
原文:
了解 网易云 :
网易云官网:
新用户大礼包: